
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,我会很高兴~
写得这么详细是因为第一次对虚拟机类pwn题的学习(在此之前只学过很简单的栈的知识),也是第一次见到大比赛的题
本文只是对原文的一些摘抄以及自己的一些理解,细节都在原文(强推)
虚拟机概述
什么是虚拟机
这里的虚拟机指的是一种解释器,能够运行汇编语言编写的程序的程序。
我们编写虚拟机是为了:了解计算机的更底层的原理以及增加对vm_pwn的逆向能力
同时我们可以学到一种用数据来模拟现实的思想(算法中的数据结构类也有这种思想)
虚拟机的种类
模拟硬件的虚拟机,这类虚拟机需要模拟哪些硬件要看它的使用场景,这些虚拟机通常被称为模拟器,但二者还是有一些区别
另外一些虚拟机则完全是虚构的,而非用来模拟硬件。这类虚拟机的主要用途是使软件开发更容易,例如跨平台运行汇编,也就是我们这次编写的虚拟机
编译器也解决了类似的跨平台问题,它将标准的高级语言编写的程序编译成能在不同 CPU 架构上执行的程序。 相比之下,虚拟机的跨平台方式是自己创建一个标准的CPU架构,然后在不同的物理设备上模拟这个 CPU 架构。
LC-3 架构
与 x86 相比 ,LC-3 的指令集更 加简化,但现代 CPU 的主要思想其中都包括了
用数据模拟机器最基础的硬件组件
内存
LC-3 使用16条地址线。这意味着它可以寻址65,536(2的16次方) 个不同的内存位置。每个地址对应一个内存单元,每个单元可以存储一 个 16-bit 的值。这意味着它总共可以存储 128KB 数据(64k*2,16位为2字节,每个字节表示一个数据)
我们用一个数组来模拟lc3的内存,uint16_t为它的内存单元 UINT16_MAX=65,536为它的最大值,所以uint16_t memory[UINT16_MAX]为该内存;
寄存器
一个寄存器就是 CPU 上一个能够存储单个数据的槽,因为寄存器很少,所以实际操作的思路是从内存加载数据到寄存器,然后将计算结果放到寄存器,最后将最终结果再写回内存
寄存器就是一段小的内存,依然用数组定义他们。
利用枚举类型+数组定义的方式可以直观的知道数组下标的意义
指令集
指令集是一个数据索引表,当表中内容和操作码对应上时就通过分支去执行对应的操作
条件标志位
同样是一个信息表,配合jz,jnz等指令用来完成诸如 if (x > 0) { … } 之类的逻辑条件
汇编指令
本质上就是一个 16 比特指令组成的数组,每一比特代表不同的信息,一般前4比特表示操作码,后面的表示操作数
比如:add a,b
这些文本字符只是标签,一种标签对应一种数据(指令),而其对应的比特数据可以被虚拟机执行,也就对应了一种操作(也就是说汇编指令跟变量的作用一样,只是让我们更好理解程序),而我们编写的vm就是处理比特数据的
机器执行流程
这是我们学习最重要的一部分,因为根据不同的人来写,程序的结构是千千万万的(不同的人可能会有不同的数据的定义方法,函数实现等),但核心的程序执行流是不变的 程序执行流是一种逻辑流,在抽象的角度完成了需要实现的功能,我们拿算法来举例,递推和递归虽然可以完成相同的任务,但二者的思路不一样,因此执行流也不一样(差异巨大)。 一般一种思路对应一种执行流。 逆向的代码再花哨,只要执行流相同,那么大体的代码结构也一样,这也是我们手搓vm的原因。
一般执行流
- 从 PC 寄存器指向的内存地址中加载一条指令
- 递增 PC 寄存器
- 查看指令中的 opcode 字段,判断指令类型
- 根据指令类型和指令中所带的参数执行该指令
- 跳转到步骤 1
指令实现
指令无非就两种,一种是运算指令(and,add之类的),另一种是流程改变指令(ret,jum之类的),但无论是哪种,都是对寄存器(因为指令是给cpu来执行的,所以必须用寄存器作为对象)中的值进行读写罢了,只是后者读写的是最特殊的ip寄存器 所以我这里就记录这两种指令的实现,其他是都是差不多
add指令
详见原文和lc-3指令规范,这里我们只对规范和实现代码解读
- 前四个比特代表操作码,所以理论上我们可以实现2的4次方个指令
- 寄存器都只用三个比特位表示,这里只是寄存器的索引,所以理论上lc-3最多支持2的3次方个寄存器作为操作数(实际上我们前面定义寄存器的时候也就只定义了8个通用寄存器)
- 一个比特的模式位,某些指令同时支持立即数和寄存器做操作数(比如add指令),所以需要这个信息来区分两种模式
- 立即数:5个比特位,只支持2的5次方范围,因此只适合对一个比较小的值进行运算
- 寄存器模式下需要用到三个寄存器,也就是说
ADD R2 R0 R1就是r2=f(r0,r1),其中f表示将输入的两个值相加并返回加和的结果
一些实现细节
- 为了加快机器的计算,我们需要将二进制数的位数相匹配才能计算,因此我们需要将立即数和寄存器模式的数值进行扩展
- 此时我们需要对位运算足够熟练
uint16_t sign_extend(uint16_t x, int bit_count) {
if ((x >> (bit_count - 1)) & 1) {
/* 取出最高位的符号位,&1: 检查符号位是否为1。如果结果为1,表示 x 是一个负数,则进行掩码拓展 */
x |= (0xFFFF << bit_count);/* 0xFFFF << bit_count生成一个掩码;|运算将掩码应用到原始值 x 上 */
}
return x;
}
有值写到寄存器时,我们 需要更新这个标记,以标明这个值的符号
/* 传入需要检查的寄存器的索引 */
void update_flags(uint16_t r) {
if (reg[r] == 0) {
reg[R_COND] = FL_ZRO;
}
else if (reg[r] >> 15) { /* 检查这个被写入值的寄存器的最高位(符号位) */
reg[R_COND] = FL_NEG;/* 如果最高位为1,则设置条件标记为负标志(FL_NEG),表示结果为负数 */
} else {
reg[R_COND] = FL_POS;
}
}
然后就可以实现add了
{ /*0x7 是一个二进制数 00000111用于掩码操作,利用同状态才为真的性质可以去除掉无关位数据的干扰*/
uint16_t r0 = (instr >> 9) & 0x7; /* destination register (DR) */
uint16_t r1 = (instr >> 6) & 0x7; /* first operand (SR1) */
uint16_t imm_flag = (instr >> 5) & 0x1; /* whether we are in immediate mode */
if (imm_flag) {
uint16_t imm5 = sign_extend(instr & 0x1F, 5);
reg[r0] = reg[r1] + imm5;
} else {
uint16_t r2 = instr & 0x7;
reg[r0] = reg[r1] + reg[r2];
}
update_flags(r0);
}
Branch
lc-3规范:
- 三个比特位表示条件位:z,n,p,分别表示零标志,负标志,正标志,分别对应于FL_ZRO,FL_NEG,FL_POS
- 9个比特位表示与pc寄存器(也就是ip寄存器)的偏移,用于计算跳转的地方
实现
{
uint16_t pc_offset = sign_extend((instr) & 0x1ff, 9);
uint16_t cond_flag = (instr >> 9) & 0x7;/*获取条件位(因为这个指令的操作码是0000,所以我们直接&取数据就行了)*/
if (cond_flag & reg[R_COND]) {/*检查标志位,判断前一次指令的计算结果,此时就用上了update_flags(r0)*/
reg[R_PC] += pc_offset;/* 写入pc寄存器,改变执行流 */
}
}
Trap Routines(中断陷入例程)
可以理解为系统调用,trap code就是系统调用号,我们这里用系统调用封装的c语言来实现系统调用(有点难崩)
PUTS(同样只记录这一个)
- 规范:将这个字符串的地址(lc3的字符串是存储在一个连续的内存区域)放到 R0 寄存器,然后触发 trap
{ /*基地址+R0中的偏移获取字符串的起始地址*/ uint16_t* c = memory + reg[R_R0]; while (*c) { putc((char)*c, stdout);/* 强制转换成char类型输出 */ ++c;/* 递增直至遇到以空字符结尾的字符串 */ } fflush(stdout); /*刷新输出缓冲区,确保任何尚未输出到标准输出(通常是终端或控制台)的数据立即被写出*/
加载程序
首先我们要了解这个虚拟机处理的文件是怎样的(一个指令流和相应的数据),然后才能想办法把文件数据写入到内存
程序的前 16 比特规定了这个程序在内存中的起始地址,这个地址称为 origin。因此 加载时应该首先读取这 16 比特,确定起始地址,然后才能依次读取和放置后面的指令及数据
void read_image_file(FILE* file) {
uint16_t origin; /* the origin tells us where in memory to place the image */
fread(&origin, sizeof(origin), 1, file);
origin = swap16(origin);/* 转换为大端序 */
uint16_t max_read = UINT16_MAX - origin;/* 除去origin后剩余的文件数据 */
uint16_t* p = memory + origin;/* 文件数据应该被放置在物理机内存中的起始位置 */
size_t read = fread(p, sizeof(uint16_t), max_read, file);/* 读取 max_read 个 uint16_t 类型的数据。将文件数据按lc-3的内存结构排列在物理机内存中 */
/* swap to little endian */
while (read-- > 0) {
*p = swap16(*p);
++p;
}
}
内存映射寄存器
void mem_write(uint16_t address, uint16_t val) {
memory[address] = val;
}
uint16_t mem_read(uint16_t address)
{
if (address == MR_KBSR) {
if (check_key()) {
memory[MR_KBSR] = (1 << 15);/*当访问键盘输入寄存器时,写入操作会对内存状态寄存器执行写入操作。
表面此时把键盘的输入信息存到了这个寄存器中*/
memory[MR_KBDR] = getchar();
} else {
memory[MR_KBSR] = 0;/* 没有键按下,清空 KBSR */
}
}
return memory[address];
}
逆向
原题目是:2024 · CISCN长城杯avm
main函数结构
unsigned __int64 __fastcall main(__int64 a1, char **a2, char **a3)
{
memset(s, 0, 0x300uLL);
write(1, "opcode: ", 8uLL);
read(0, s, 0x300uLL);
sub_1230(&unk_40C0, s, 0x300LL);
sub_19F1(&unk_40C0);
}
程序让我们输指令到栈上的一段初始化的空间,这里就是指令段
没什么信息了,进去函数看一下
sub_1230函数
_QWORD *__fastcall sub_1230(_QWORD *a1, __int64 a2, __int64 a3)
{
_QWORD *result; // rax
int i; // [rsp+24h] [rbp-4h]
a1[33] = a2;
a1[34] = a3;
result = a1;
a1[32] = 0LL;
for ( i = 0; i <= 31; ++i )
{
result = a1;
a1[i] = 0LL;
}
return result;
}
传入一个bss段的qword数组,把指令段,指令尺寸都接在了这个数组后面,然后初始化了数组前面的数据,但保留了接上去的数据,也就是说这个数组里面的数据有不同的意义,所以可以推断这个是结构体
修结构体的部分就不细说了(基本和前面定义lc-3物理硬件的时候一样),准备后面在逆向专门写一篇文章总结,这里大致的思路就是顺着前面的开发经验然后再根据元素的尺寸和后面sub_19F1函数推断出成员数据,但是一般情况下用gdb好分析一点
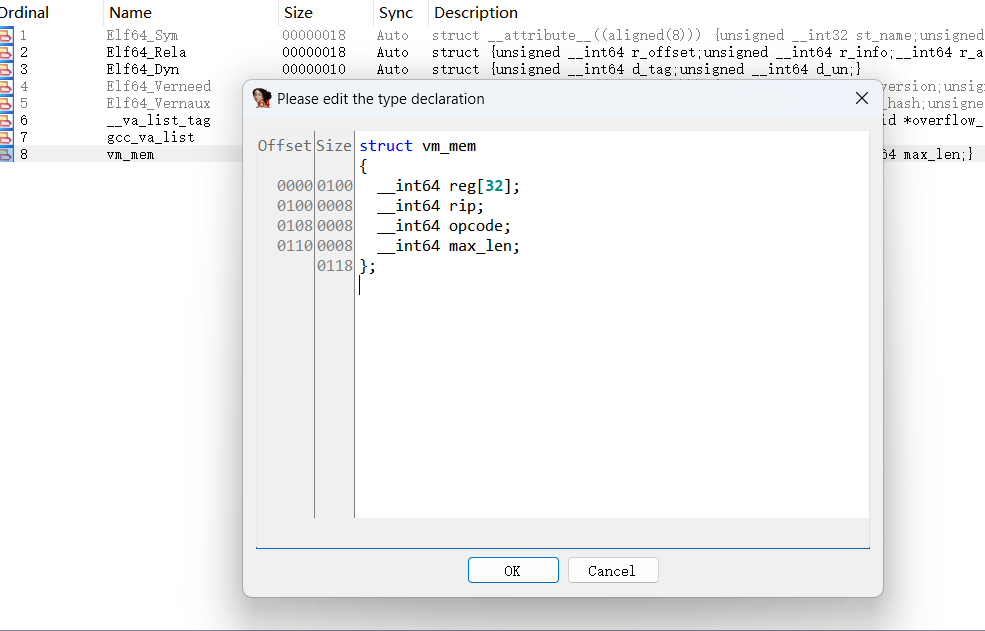
修完后就是这样,就是一个初始化函数
vm_mem *__fastcall sub_1230(vm_mem *vm_mem, char *a2, __int64 a3)
{
vm_mem *result; // rax
int i; // [rsp+24h] [rbp-4h]
vm_mem->opcode = a2;
vm_mem->max_len = a3;
result = vm_mem;
vm_mem->rip = 0LL;
for ( i = 0; i <= 31; ++i )
{
result = vm_mem;
vm_mem->reg[i] = 0LL;
}
return result;
}
另一个函数也就很清楚了
sub_19F1函数
unsigned __int64 __fastcall disassemble(vm_mem *a1)
{
unsigned int high_bit; // [rsp+1Ch] [rbp-114h]
char s[264]; // [rsp+20h] [rbp-110h] BYREF
unsigned __int64 v4; // [rsp+128h] [rbp-8h]
memset(s, 0, 0x100uLL); /* 这里用结构体寻址+索引来定位 */
while ( a1->rip < (unsigned __int64)a1->max_len )
{
high_bit = *(_DWORD *)&a1->opcode[a1->rip & 0xFFFFFFFFFFFFFFFCLL] >> 28;/*第一字节为标志位,
&0xFFFFFFFFFFFFFFF保证四字节对齐,可以推断出为32位*/
if ( high_bit > 0xA || !high_bit )
{
puts("Unsupported instruction");
return v4 - __readfsqword(0x28u);
}
((void (__fastcall *)(vm_mem *, char *))to_opcode[high_bit])(a1, s);/* 点进这个to_opcode数组,可以看到对应指令的处理函数,一个一个逆就行了 */
}
}
add指令
有了开发经验除了最后两个指令其他指令都可以一眼看出来,直接看最后部分就行了,知道是什么指令再反过去推出指令规范就行了
点进去第一个sub_129A然后复原一下结构体
void __fastcall add(vm_mem *a1)
{
unsigned int used_opcode; // [rsp+10h] [rbp-10h]
used_opcode = *(_DWORD *)&a1->opcode[a1->rip & 0xFFFFFFFFFFFFFFFCLL];/* 指令码为32位 */
a1->rip += 4LL;/* 自增4指向下一个指令 */
a1->reg[used_opcode & 0x1F] = a1->reg[HIWORD(used_opcode) & 0x1F] + a1->reg[(used_opcode >> 5) & 0x1F];
}
0-4位为目标寄存器,5-9位和16-20位是寄存器(5位刚好对应32个寄存器),31-28为操作码(其他的不知道,可能是立即数)
store指令
char *__fastcall store(vm_mem *a1, char *sta_base)
{
char *result; // rax
unsigned int used_opcode; // [rsp+20h] [rbp-20h]
char *v4; // [rsp+30h] [rbp-10h]
used_opcode = *(_DWORD *)(a1->opcode + (a1->rip & 0xFFFFFFFFFFFFFFFCLL));
a1->rip += 4LL;
result = (char *)(unsigned __int8)ffh;
if ( (unsigned __int8)(a1->reg[(used_opcode >> 5) & 0x1F] + BYTE2(used_opcode)) < (unsigned __int8)ffh )
/*取出右边移位5之后取出来的值对应的寄存器的值(觉得说得绕的话多看看代码),加上右移十六位之后的opcdoe值相加*/
{
v4 = &sta_base[(unsigned __int16)(a1->reg[(used_opcode >> 5) & 0x1F] + (HIWORD(used_opcode) & 0xFFF))];/* 寄存器值+偏移获取栈的地址 */
*(_QWORD *)v4 = a1->reg[used_opcode & 0x1F];/* 把目标寄存器的值传给栈 */
return v4;
}
return result;
}
Load函数是通过移位也就是一个字节一个字节的取赋值所以ida逆向得有点逆天,看汇编+把store反过来看就可以了
漏洞也就是在这两个指令,这里对于索引进行了取单字节的操作(也就是(unsigned __int8)这个操作),这就导致无论实际上的操作数是多大,都会被截断后再check,会导致这里的check失效,可以越界读写栈上的内容
漏洞利用
这里用rop的思想利用程序定义的指令去构造"shellcode",所以首先我们要根据原题重构这些指令
具体的rop就是通过load指令读取栈中的一些地址,比如libc中函数的地址,通过sub, add指令的功能减去偏移,获得到偏移之后就用store指令将system(“/bin/sh”)写入到返回地址
重构指令
def get_opt(num):
return (num & 0xf) << 28
""" target为目标寄存器,a,b为操作数 """
def prepare_num(target,a,b):
payload = (target & 0x1f) + ((a &0x1f) <<5) + ((b & 0x1f) << 16)
""" 确保只有最低5位是有效数据(寄存器索引都是5位) """
return payload
def add(target,a,b):
payload = prepare_num(target,a,b)
payload |= get_opt(1)
""" 将指令和操作数合并 """
return payload.to_bytes(4,byteorder='little')
def set(target,idx1,idx2):
""" make buff[idx1 + idx2] to regsiter[target] """
if ((idx1 & 0x1f) + (idx2 &0xff) < 0xff):""" 确保数据能过检查 """
payload = ((idx1 & 0x1f) << 5) + ((idx2 & 0xfff) << 16) + (target & 0x1f)""" 越界修改 """
payload |= get_opt(9)
return payload.to_bytes(4,byteorder='little')
else:
print("error : index out of range")
exit(1)
大概就是这样的思路,我们输入操作数,这些函数就直接给我们返回指令(我们要的shellcode),其他的照着写就行了
调试
现在根据观察程序的信息来确定具体的数据,由于一开始opcode的buf里面没有值,所以我们得用load先获取一个栈上的数据数据来方便填充,并提前布置好一堆数据来方便后面调用各种指令的时候使用
再以__libc_start_call_main+128 为基准(不知道为什么其他的libc函数偏移量好像都不固定),使用各种运算符得到system、pop_rdi、binsh、ret的地址,最后利用store将他们布置在栈上